Fixed-point number
From MSX Game Library
Un nombre à virgule fixe, c'est simplement un nombre réel (par ex. 3,14) qu'on va coder sur un nombre entier en lui appliquant un facteur (un multiplicateur). L'intérêt est de pouvoir manipuler de nombres avec une précision inférieur à 1, tout en gardant les bonnes performances de manipulation de nombre entier.
Contents
Principe
Pour comprendre le principe, il suffit d'imaginer un programme qui utiliserait le mètre comme unité finale mais qui aurait besoin à un moment de pouvoir déplacer un objet de moins d’une unité, disons 0,2 m. Vu qu'il serait bien trop lourd pour nos vénérables MSX de travailler avec de vrais nombres à virgule flottante (comme les float du C), l'astuce pourrait simplement être de stocker les nombres et de faire ses calculs sous la forme Val = mètres * 100 (en cm donc), puis de convertir en mètre quand c'est nécessaire (mètres = Val / 100). Du coup, pour ajouter 0,2 m, on ajouterait la valeur entière 0,2 * 100 (c-à-d 20). À l'inverse, le nombre entier 4213 représenterait en fait 42,13 m. Un tel format serait un nombre à virgule fixe de 2 décimales (100). Simple. :)
Format Qm.n
Comme les divisions/multiplications par 100 sont coûteuses, on va plutôt utiliser des facteurs puissance de 2 (1, 2, 4, 8, 16, etc.) comme base pour la partie fractionnelle. Du coup, les divisions/multiplications peuvent être remplacés par des décalages de bits qui sont énormément moins coûteux. Sur un entier 8 ou 16-bits (les 32-bits sont souvent trop coûteux pour nos Z80), on va donc décider du nombre de bits qui serviront à coder la partie entière et de ceux (le reste) qui serviront à coder la partie fractionnelle. C’est le format Q ! Ou plutôt « Qm.n ». (cf. Article "Q" sur Wikipédia)
Par ex., un nombre 8-bits codé au format Q4.4, utilise 4-bits pour l’entier et 4-bits pour la fraction. Pour convertir une valeur en Q4.4, il suffit de décaler le nombre 4 fois vers la gauche (x << 4), Pour convertir un Q4.4 en valeur, il suffit de décaler le nombre 4 fois vers la droite (x >> 4). Si on l’utilise pour stocker un nombre non signé, on pourra coder dans un Q4.4 des nombres allant de 0 à 15,9375 (255/16) avec une précision de 0,0625 (1/16). On peut utiliser avec le Q4.4 n’importe quelles opérations mathématiques de base tant que tous les termes sont au même format.
A noter que pour les entiers signés, certains excluent le bit de signe dans la notation. Du coup, Q7.8 ⇒ 1-bit de signe, 7-bits entier, 8-bits fractionnel.
Exemples
Il existe autant de Q qu’ils y a de combinaisons de bits (ne pas sortir cette phrase de son contexte, hein :oups). Voici quelques exemples que j’utilise : - Q2.6 : Entier 8-bits qui permet de coder des chiffres entre -1,0 et 1,0 avec une précision de 0,015625. Très utile pour stocker des vecteurs de direction par ex. - Q8.8 : Entier 16-bits avec partie entière et fractionnelle sur 8 bits. Très performant à utiliser avec un nombre non-signé. Sinon, il faut prendre qq précautions. - Q6.10 : Entier 16-bits avec partie entière de 6 bits et fractionnelle sur 10 bits. Permet de manipuler les données en Ko (avec un facteur 1024). Utile pour les petits nombre ayant besoin d’une très grande précision (~0,001).
Conversion
On peut évidemment passer d'un Q à l'autre avec de simple décalage de bits (:oups). Par ex. : - Q4.4 << 2 ⇒ Q2.6 - Q8.8 >> 4 ⇒ Q12.4 (en cas de valeur signée négative c'est un peu plus compliqué car il faut préserver le signe)
Liste exhaustive
Voici l'ensemble des format Qm.n possibles pour les entiers 8 et 16-bits avec leur valeur de précision et leurs bornes :
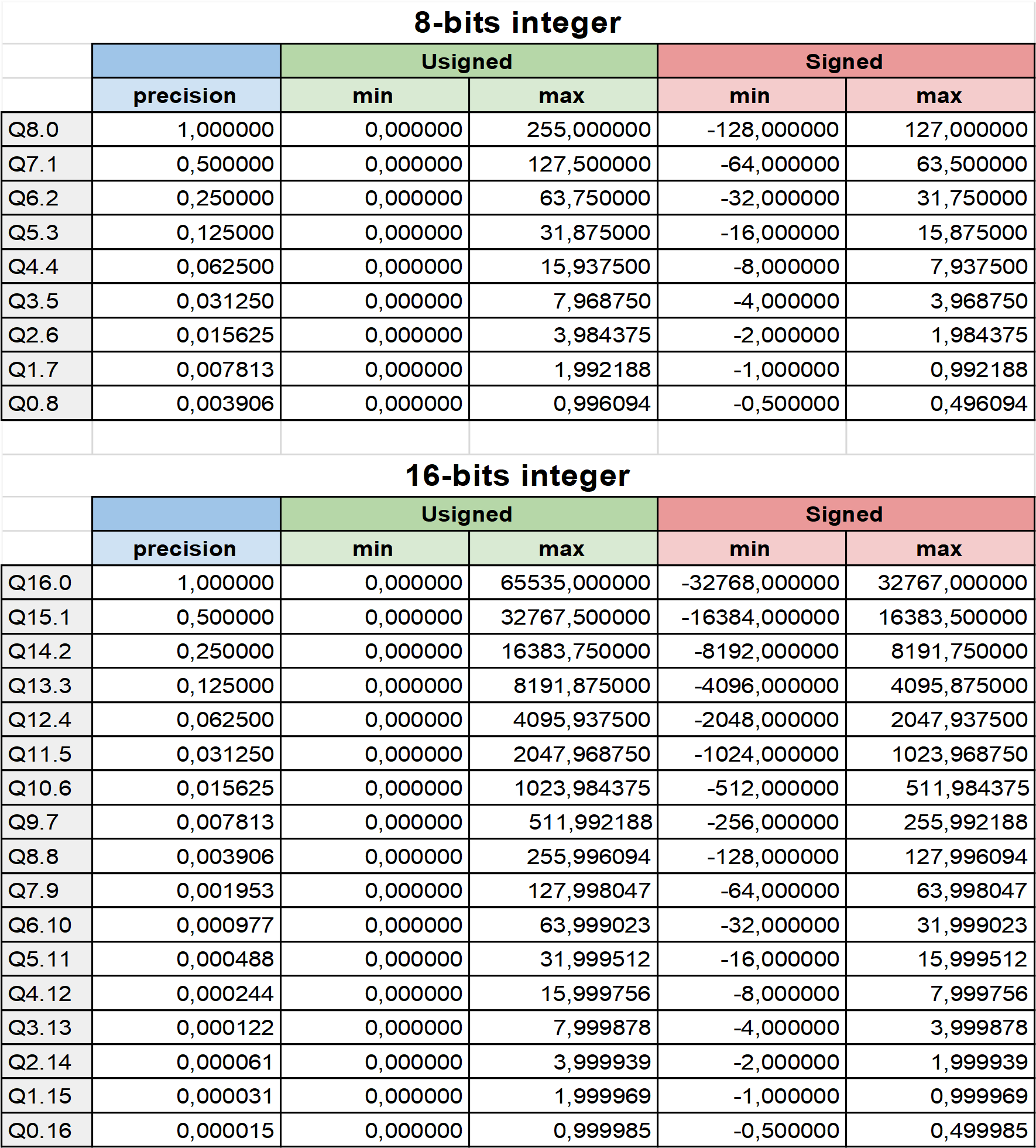
Dispo aussi au format PDF: Qm.n.pdf.
Exemple d'utilisation
Imaginons qu'on doive calculer l'expression 'a x cos(b)', avec 'a' un entier 8 bits.
On sait que cos(b) est un nombre réel compris entre -1 et 1. On va utiliser une simple table qui va nous donner la valeur de cos(b) pour b. Partons du principe que les valeurs exactes -1 et 1 seront gérées séparément (par exemple à l'aide d'un test avant le calcul), et que l'on ne gère que les angles de 0° à 90°. Donc, on doit stocker des valeurs comprises entre 0 et 0,999999. Pour stocker ce genre de valeurs, le format Q0.8 non signé est parfait.
Prenons par exemple cos(45°) = racine carrée (2)/2 = 0.70710678118 Pour coder ce nombre en Q0.8 non signé, il suffit de le multiplier par 256 : 0.70710678118 x 256 = 181.019335984 On ne peut évidemment pas prendre les décimales, donc on ne stocke que la valeur entière : 181 (entier 8 bit).
Plaçons nous au moment du calcul, lorsqu'on veux faire, par exemple, 33 x cos(45°) = 23.3345237792 : - on prend la valeur de la table pour 45° (181) - on la multiplies par 33 - on obtient donc un entier 16 bits dont la valeur est 5973
Cet entier 16 bits est le résultat, codé en Q8.8. Normal, puisqu'en fait, on a multiplié les 2 membres de lexpression par 256 : a x (256 x cos(b)) = 256 x résultat 5973 / 256 = 23.33203125, on a donc une erreur de 0,002, ce qui est acceptable.
Et pour obtenir la valeur entière, il suffit de garder l'octet haut du résultat. 5973d = 1723h, la valeur entière est donc : 17h = 23d.
Assembleur
Exemple
Par ex., lorsqu'un programmeur voudra récupérer la valeur d'un entier 8-bits au format Q4.4, il lui suffit de faire >>4 sur la valeur. Avec en bonus, la possibilité d'utiliser le dernier bit sorti vers la droite pour faire l'arrondi.
Imaginons que le résultat d'une série d'opérations donne le nombre 58, soit en format binaire 00111010b. Ce nombre est en fait la représentation de 3,625 en Q4.4 (puisque 58/16=3,625). Lorsque l'on va faire >>4 sur cette valeur pour récupérer la valeur entière, il restera bien 3 dans le nombre (0011b), et le dernier bit sorti à droite sera 1. Ce qui peut être alors utilisé pour décider de faire l'arrondi vers l'entier supérieur (ou pas).
Exemple de l'arrondi vers l'entier supérieur en Q4.4 d'une valeur contenue dans 'a' :
Copier vers le presse-papierCode :
<syntaxhighlight lang="c">
- valeur de a >> 4
srl a srl a srl a srl a
- ajout du carry (qui contient le dernier bit sorti à droite)
adc 0 <syntaxhighlight>
Code optimal
Voici les façons optimales (en nombre de cycles) pour faire les décalages de bits en Z80 : Copier vers le presse-papierCode ASM :
- a >> 1 (10cc)
srl a
- a >> 2 (18cc)
rrca rrca and a, #0x3F
- a >> 3 (23cc)
rrca rrca rrca and a, #0x1F
- a >> 4 (28cc)
rlca rlca rlca rlca and a, #0x0F
- a >> 5 (23cc)
rlca rlca rlca and a, #0x07
- a >> 6 (18cc)
rlca rlca and a, #0x03
- a >> 7 (13cc)
rlca and a, #0x01
- a << 1 (5cc)
add a, a
- a << 2 (10cc)
add a, a add a, a
- a << 3 (15cc)
add a, a add a, a add a, a
- a << 4 (20cc)
add a, a add a, a add a, a add a, a
- a << 5 (23cc)
rrca rrca rrca and a, #0xE0
- a << 6 (18cc)
rrca rrca and a, #0xC0
- a << 7 (13cc)
rrca and a, #0x80
Chaque format Qm.n a donc un coup de conversion différents. Temps de conversion in/out : - Q7.1 : 15cc - Q6.2 : 28cc - Q5.3 : 38cc - Q4.4 : 48cc - Q3.5 : 46cc - Q2:6 : 36cc - Q1:7 : 26cc
Langage C
Et pour les utilisateurs de C, il est conseillé de passer par des macros de conversion.
Par ex. : Copier vers le presse-papierCode C : // Unit conversion (Pixel <> Q10.6)
- define UNIT_TO_PX(a) (u8)((a) / 64)
- define PX_TO_UNIT(a) (i16)((a) * 64)
a On laisse les multiplications/divisions par 64 pour permettre au compilateur de pouvoir adapter ses opérations en fonction du type de data qu'on lui donne. Si on prend une variable int16 x qui contient un nombre au format Q10.6, on peux faire ce genre d'opérations : Copier vers le presse-papierCode C :
- define PI PX_TO_UNIT(3.14159265f) // Le compilateur va faire la conversion en float, puis convertir en int (précision optimale)
uint8 nbPixel = 10; x += PX_TO_UNIT(nbPixel); // Le compilateur va faire la conversion via des décalages de bits (vitesse optimale) if(x > 2*PI) // A noter une petite perte de précision car le x2 va être fait après la conversion en int
x = PI;
L'autre gros avantage, c'est qu'on peux ainsi changer la précision de son unité sans devoir retoucher tout son code.